
Background
I was asked to administrate all users and resources of my employer's Amazon Web Services (AWS) a few months ago. To demonstrate that I have the appropriate training to take on this role, an AWS Certified Solutions Architect diploma was required. During my online course with A Cloud Guru I learned about serverless architectures. After passing the certification exam, I decided to experiment with serverless architecture to determine if they can help me out in my daily work as a data scientist. I am happy to share my experience with you below.
Introduction
This post shows how to host machine learning prediction services on the cloud with infinite scaling, zero downtime, zero maintenance, at a very low cost. By using serverless cloud services it is possible to create end to end solutions for data science projects and enable end-users to consume the insights over the Internet.
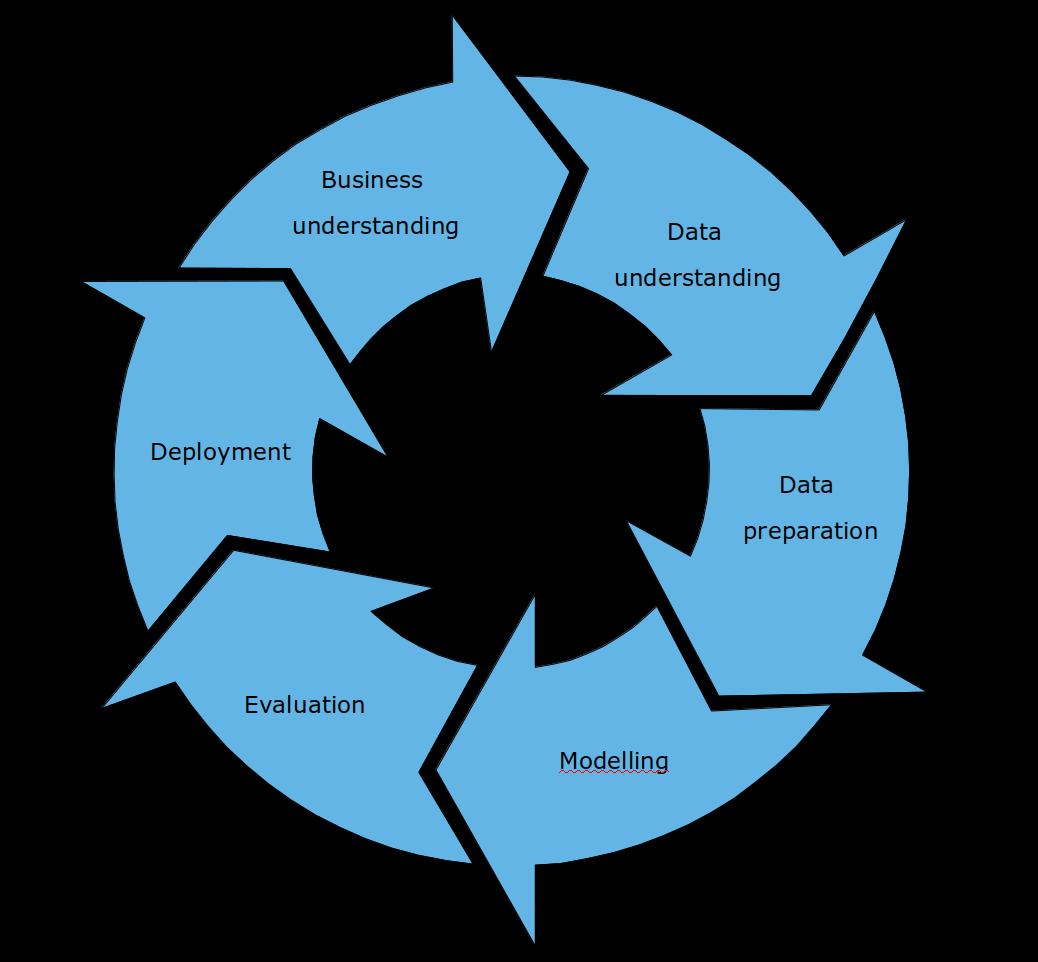 First let us back up a bit and set the stage. The data science life cycle involves
First let us back up a bit and set the stage. The data science life cycle involves
- understanding the business,
- acquire, understand and prepare the data
- train a machine learning model on the data
- validate the model and estimate uncertainties
- deploy a prediction service based on the model
The first steps of this life cycle are typically done on-premise with local tools and resources. However, at some point the users need to access the prediction service that you prepared. They cannot all connect to you laptop to consume the insights provided by your new service. A common solution is to deploy the prediction service as an API, which can be accessible only to enterprise users, or be open to anyone on the Internet depending on the project requirements.
Azure Machine Learning makes creation of an API really easy. Once your model is trained and validated, it is just a few clicks in the graphical interface and you are ready to integrate the new prediction service with web apps or Microsoft Office.
A downside to Azure Machine Learning is that the data used in the training is exposed to the Internet. For many companies this is a red flag. Either regulations prevent sensitive data from leaving enterprise data centres, or the risk appetite of the business is a significant hurdle.
But what if you could keep all enterprise confidential data on the corporate network, and only host the prediction service with a web interface? The only data being exposed to the cloud provider is the data that the user sends as input to the prediction service.
Serverless architectures provide infinite scaling, zero downtime, zero maintenance, at a very low cost. Serverless architectures have revolutionized the way we think of hosting services since its introduction in 2014, so I am going to show how to host a machine learning prediction service on AWS Lambda in addition to hosting it on the local corporate network.
Training the classifier
In the data science community scikit-learn is a very popular choice for traditional machine learning. To demonstrate how you can host a scikit-learn model as a prediction service on serverless infrastructure we must first create and train a scikit-learn model.
The example below pulls in thousands of newsgroup messages and builds a model that can detect if the topic of the discussion is guns and firearms.
# coding: utf-8
from __future__ import print_function
import numpy as np
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import SGDClassifier
from sklearn.externals import joblib
twenty_train = fetch_20newsgroups(subset='train',
shuffle=True,
random_state=42)
twenty_test = fetch_20newsgroups(subset='test',
shuffle=True,
random_state=42)
# create a list of 0 for negative labels and 1 for positive labels
y_train = [1*(label == 16) for label in twenty_train.target]
y_val = [1*(label == 16) for label in twenty_test.target]
# train the preprocessing of the data
preproc = TfidfVectorizer(max_features=5000)
_ = preproc.fit(twenty_train.data, y_train)
joblib.dump(preproc, 'preproc_cvtfidf.pkl')
# preprocess the data
X_train = preproc.transform(twenty_train.data)
X_val = preproc.transform(twenty_test.data)
# train the classifier
clf = SGDClassifier(loss='log', class_weight='balanced')
_ = clf.fit(X_train, y_train)
joblib.dump(clf, 'clf_sdg.pkl')
In a real world scenario you should spend time on validating the model, quantify sampling bias, propagate uncertainties etc, but for this tutorial the simple script above is fit for purpose.
This model is a very basic logistic regression implemented with stochastic gradient decent and TF-IDF preprocessing. Give me a shout in the comments section below if you want to see a more sophisticated text classification in another blog post.
The preprocessing and the classifier are persistified as local files. We need those to set up an independent prediction service.
Setting up a prediction service
Testing basic prediction locally
Before publishing your new gun detection model to the world you should make sure it works as intended. Simply load the model files and send some random text messages through the model.
# coding: utf-8
from sklearn.externals import joblib
pre = joblib.load('preproc_cvtfidf.pkl')
clf = joblib.load('clf_sdg.pkl')
input = ["I shot the sheriff.", "School shooting in Las Vegas. Gunman killed by police.", "Prime minister struggles to settle Brexit deal."]
X = pre.transform(input)
output = zip(input, clf.predict(X)[:], clf.predict_proba(X)[:,1])
print (list(output))
Output should look like this if all is well:
[('I shot the sheriff.', 0, 0.33693677715786069),
('School shooting in Las Vegas. Gunman killed by police.', 1, 0.5571287620731008),
('Prime minister struggles to settle Brexit deal.', 0, 0.10020190594453801)]
The output shows that the model works as intended; messages are scored higher if they contain words that suggest that the topic is firearms.
Local webservice
In preparation of hosting the prediction service on the cloud we copy the two model files to an S3 bucket. Using AWS Command Line Interface :
aws s3 cp clf_sdg.pkl s3://yourbucketname
aws s3 cp preproc_cvtfidf.pkl s3://yourbucketname
You can of course upload the files using the AWS console, or some alternative method.
Next you need to set up a virtual environment to ensure that all dependencies are available once you move the service into a Lambda function.
mkdir lambda
cd lambda/
pip install virtualenv
virtualenv lambda_demo
source lambda_demo/bin/activate
pip install scikit-learn flask boto numpy scipy zappa
We will get to Zappa later, but at the moment of writing there is a problem with one of Zappa's dependencies, so we need to forcefully install an older version.
pip install toml==0.9.2 --force-reinstall
The prediction service is going to be provided as an API written in Flask where both input and output formats will be JSON. Below is the code for my example Flask app, saved as prediction_lambda.py.
from sklearn.externals import joblib
import boto
from boto.s3.key import Key
from flask import Flask
from flask import request
from flask import json
BUCKET_NAME = 'yourbucketname'
PREP_FILE_NAME = 'preproc_cvtfidf.pkl'
PREP_LOCAL_PATH = PREP_FILE_NAME
MODEL_FILE_NAME = 'clf_sdg.pkl'
MODEL_LOCAL_PATH = MODEL_FILE_NAME
AWS_S3_HOST = 's3.eu-central-1.amazonaws.com'
app = Flask(__name__)
@app.route('/', methods=['POST'])
def index():
# retrieve message as json, should contain a payload
inMessage = json.loads(request.get_data().decode('utf-8'))
payload = inMessage[u'payload']
# assign score to documents in the payload
prediction = predict(payload)
return prediction
def load_preprocess():
# read the preprocessing from a S3 bucket
conn = boto.connect_s3(host=AWS_S3_HOST)
bucket = conn.get_bucket(BUCKET_NAME)
key_obj = Key(bucket)
key_obj.key = PREP_FILE_NAME
contents = key_obj.get_contents_to_filename(PREP_LOCAL_PATH)
return joblib.load(PREP_LOCAL_PATH)
def load_model():
# read the machine learning model from a S3 bucket
conn = boto.connect_s3(host=AWS_S3_HOST)
bucket = conn.get_bucket(BUCKET_NAME)
key_obj = Key(bucket)
key_obj.key = MODEL_FILE_NAME
contents = key_obj.get_contents_to_filename(MODEL_LOCAL_PATH)
return joblib.load(MODEL_LOCAL_PATH)
def predict(data):
# Preprocess the data
X = load_preprocess().transform(data)
# Create a dictionary containing input and scores
output = dict(zip(data, load_model().predict_proba(X)[:, 1]))
return json.dumps(output)
if __name__ == '__main__':
# listen on all IPs
app.run(host='0.0.0.0')
To read the model files that you uploaded to the S3 bucket, app needs to have access to the bucket, so read permission should be set, and credential are needed. The AWS credentials can be saved in ~/.aws/config. In my case, I created a role for my EC2 instance used for development which allows it to read and write to S3. (It goes without saying that if you do not indent to host the service on the cloud you could use local file paths instead of configuring AWS permissions.)
To host the Flask app on your local machine simply use
python prediction_lambda.py
and the service will be reachable on port 5000 of localhost. To test if the service is working send it a JSON payload as POST:
curl -X POST -H "Content-Type: application/json" -d '{"payload": ["I shot the sheriff","But I did not shot the deputy"]}' localhost:5000
If you only want to host your gun detection service on the corporate network you are done now, congratulations! In the following section we are going to deploy it as a serverless service.
Deploy to AWS Lambda
AWS Lambda let's you write code and AWS magically makes sure that the code works and scales with changing load. In theory. In reality Lambda is completely clueless of what scikit-learn is, and the same goes for any other packages you might be using in your code.
Enter Zappa. What Zappa does is take care of all the configuration of the Lambda function and the API Gateway, so you can get your local Flask app hosted as a Lambda function with minimal effort.
From the folder where you saved prediction_lambda.py, initialize Zappa:
zappa init
Once you have answered the questions you should have a file called zappa_settings.json in the local folder. Since your machine learning environment is most likely exceeding the Lambda size limit, you need to manually add "slim_handler": true to zappa_settings.json.
{
"dev": {
"app_function": "prediction_lambda.app",
"aws_region": "eu-central-1",
"profile_name": "default",
"project_name": "lambda",
"runtime": "python3.6",
"s3_bucket": "yourbucketname",
"slim_handler": true
}
}
To deploy, and later update the deployed Lambda function, simply type
zappa deploy dev
zappa update dev
respectively. To see more information of the Lambda function the status command is very handy.
(lambda_demo) ubuntu@ec2devbox:~/PredictLambdaDemo/lambda$ zappa status
(toml 0.9.2 (/home/ubuntu/PredictLambdaDemo/lambda/lambda_demo/lib/python3.6/site-packages), Requirement.parse('toml>=0.9.3'), {'zappa'})
Status for lambda-dev:
Lambda Versions: 3
Lambda Name: lambda-dev
Lambda ARN: arn:aws:lambda:eu-central-1:070741064749:function:lambda-dev
Lambda Role ARN: arn:aws:iam::070741064749:role/lambda-dev-ZappaLambdaExecutionRole
Lambda Handler: handler.lambda_handler
Lambda Code Size: 10336816
Lambda Version: $LATEST
Lambda Last Modified: 2017-12-08T13:59:41.904+0000
Lambda Memory Size: 512
Lambda Timeout: 30
Lambda Runtime: python3.6
Lambda VPC ID: None
Invocations (24h): 6
Errors (24h): 0
Error Rate (24h): 0.00%
API Gateway URL: https://qdb669kwf9.execute-api.eu-central-1.amazonaws.com/dev
Domain URL: None Supplied
Num. Event Rules: 1
Event Rule Name: lambda-dev-zappa-keep-warm-handler.keep_warm_callback
Event Rule Schedule: rate(4 minutes)
Event Rule State: Enabled
Event Rule ARN: arn:aws:events:eu-central-1:070741064749:rule/lambda-dev-zappa-keep-warm-handler.keep_warm_callback
The API Gateway URL: indicates the new home of your gun detection service.
Confirm that the service is working
Once the new Lambda service is up and running you can call it using curl like you did when testing locally, but exchanging the endpoint from localhost:5000 to the API Gateway URL.
curl -X POST -H "Content-Type: application/json" -d '{"payload": [
"Trump Bannon row: White House lawyers threaten former aide","Caravan self-defence shotgun killer jailed for firearm possession"
]}' https://qdk769zwf8.execute-api.eu-central-1.amazonaws.com/dev
{
"Caravan self-defence shotgun killer jailed for firearm possession": 0.7338601611795328,
"Trump Bannon row: White House lawyers threaten former aide": 0.14908094037784062
}
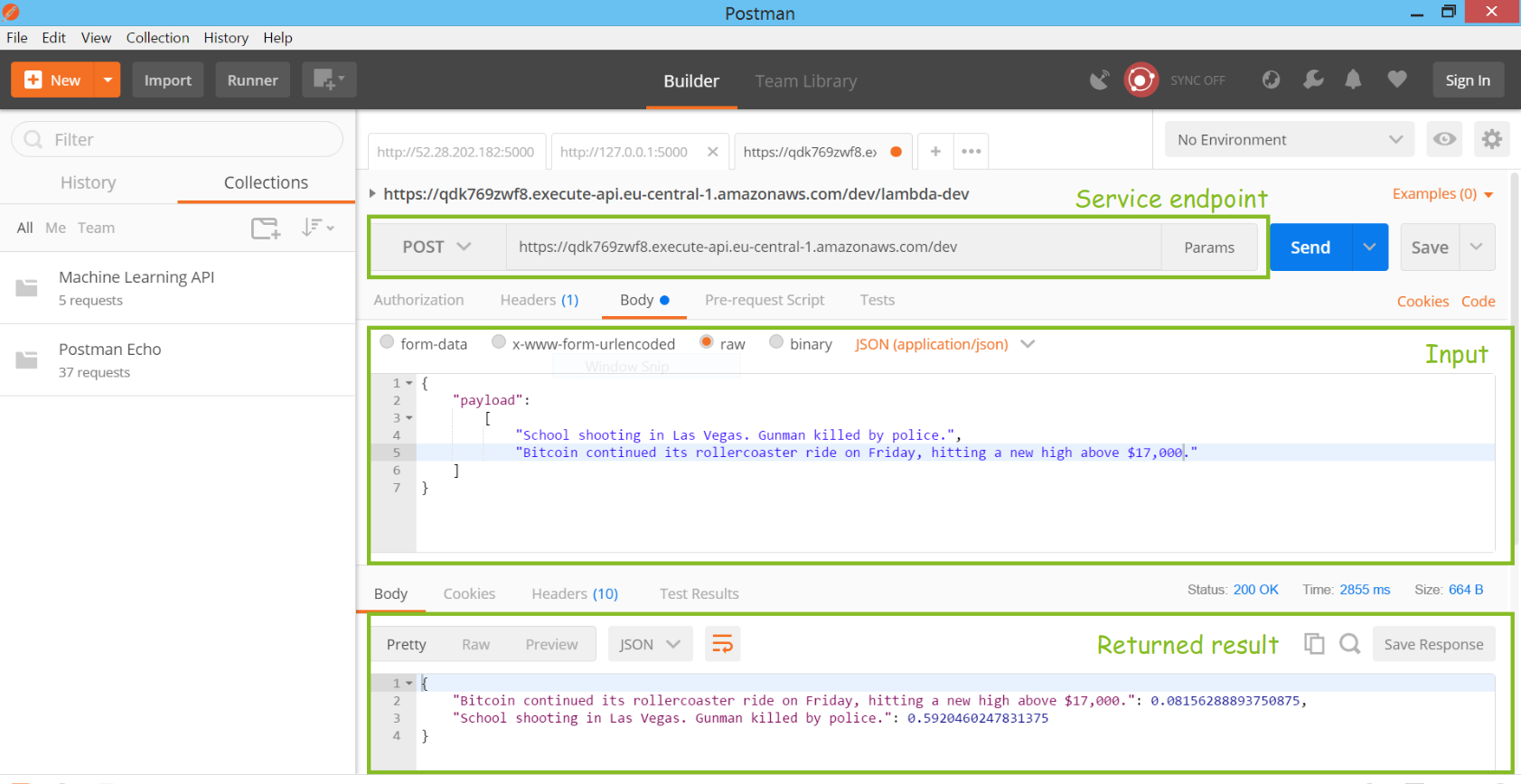
If you prefer a graphical interface you could use Postman. Provide the endpoint and payload as in the screenshot below, and you should receive a JSON document back with the scores if everything is working as intended.
Why not use a web server?
At this point you might wonder why we make all this effort to create a Lambda function to host the prediction service when you could host the Flask app on a traditional web server. For example, you could launch an AWS EC2 instance, run the Flask app on this instance, and configure the network to allow traffic to the app.
One reason is fault tolerance and availability. If the instance goes down for some reason, you would need to set up a health check to detect it, then automatically launch a new instance to host the Flask app. In addition to the extra work that means for yourself, the service would be unavailable for a minute or so while the new instance is powering up. Depending on the use case this can be a deal breaker.
A second reason is scalability. If the number of users increases you would need to make use of load balancers and launch copies of your instance through auto scaling groups to ensure that your instance is not over crowded. Likewise, you probably want to scale down the number of instances to save money when the load decreases.
The third reason is cost effectiveness. The first one million requests to AWS Lambda each month is free. The charges outside of this free tier are very affordable and I struggle to find a scenario where a serverless architecture would be less cost effective than a solution with servers.
The downside I see with AWS Lambda is that it is hard to understand errors and perform bug fixing. For this reason, I find local testing to be vital to the data science life cycle. I used a t2 micro EC2 instance to test the prediction service used in this demo before deploying it as a serverless service.
Summary
If you followed all the steps you should now have a live web service that can score text documents depending on their likelihood to discuss weapons and firearms.
A software engineer can now be add this service as a component of a product. For example, you could add a frontend to provide the text input and return the scores, or you could integrate it with a program running locally.
The ability to deploy the prediction service independently of the training of the model, enables organizations to benefit from the high availability and low cost of a serverless solution while retaining full control of the data used in training the machine learning model.
Please let me know if you have comments or questions below.
Comments !